정렬 알고리즘 이론 : maru20564.tistory.com/9
C++ 정렬(Sorting) 알고리즘 정리(1) - 이론
Intro 정렬 : 데이터를 특정한 기준에 따라 순서대로 나열하는 것. ex) 오름차순, 내림차순 데이터가 랜덤하게 분포해있으면 실제로 정보를 얻거나 사용하기 힘들기 때문에 보통 데이터를 사용하
maru20564.tistory.com
Intro
선택, 삽입, 퀵, 병합 정렬 알고리즘을 C++ 코드로 구현해보자. 정렬 기준은 오름차순으로 한다.
정렬에 걸리는 시간복잡도를 알아보기 위해 프로그램의 수행 시간을 측정할 것이다.
시간 복잡도를 알아보는 array 크기는 500으로 잡고 값의 범위는 1000으로 잡을 것이다.
난수를 발생시켜 값을 임의로 랜덤하게 넣어줄 것이다.
그에 따른 main 함수는 다음과 같다.
#include <iostream>
#include <cstdlib> //rand(), srand()
#include <ctime> //time(), clock()
using namespace std;
void sort(int arr[], int n) {
//sorting
return;
}
int main(void)
{
srand((unsigned int)time(NULL)); //seed값으로 현재시간 부여
int arr[500] = { 0, };
int n = 500;
clock_t start, end;
//arr에 random한 난수로 초기화
for (int i = 0; i < n; i++)
arr[i] = rand() % 1000;
start = clock(); //시간 측정 시작
sort(arr, n); //정렬 함수
end = clock(); //시간 측정 종료
//정렬하는데 걸린 시간 출력 (단위 : ms)
cout << (double)(end - start) << "ms" << endl;
return 0;
}
이제 저 sort 함수를 종류별로 만들어 보자.
선택 정렬 (Selection Sort)
- 코드
void selection_sort(int arr[], int n)
{
for (int i = 0; i < n; i++) {
int min = i; //최솟값
int temp;
for (int j = i; j < n; j++) {
//i ~ n까지 정렬되지 않은 배열 중 가장 최솟값이 어디있는지 탐색
if (arr[j] < arr[min])
min = j; //최솟값의 index
}
//i번째 값과 최솟값을 swap
temp = arr[min];
arr[min] = arr[i];
arr[i] = temp;
}
}
- 실행 결과 및 정렬 진행 과정

* 각 정렬 결과 화면은 알아보기 쉽도록 크기 10인 array를 사용하였다.
* 정렬 진행 과정은 정렬 중간에 현재 배열을 출력시키는 코드를 추가하면 된다. (위 코드에서는 생략하였음)
정렬 단계를 확인해보았을 때 앞의 index부터 차례대로 swap되면서 정렬된다.
같은 값이 있어도 잘 정렬되는 것을 확인할 수 있다.
삽입 정렬 (Insertion Sort)
- 코드
void insertion_sort(int arr[], int n)
{
for (int i = 1; i < n; i++) { //0번째 index는 이미 정렬됐기 때문에 1부터 시작
int key = arr[i]; //삽입할 원소
int j; //현재 위치 저장
//삽입할 원소 앞에서부터 배열의 맨 앞까지 차례대로 검사
for (j = i - 1; j >= 0; j--) {
//key값보다 크다면 하나씩 뒤로 밀어준다.
if (arr[j] > key)
arr[j + 1] = arr[j];
//key값보다 작거나 같아지면 탈출
else
break;
}
//현재 위치에 key값을 넣는다. (반복문 돌며 --가 됐기 때문에 다시 +1을 해준다)
arr[j+1] = key;
}
}
- 실행 결과 및 정렬 진행 과정

j번째의 원소가 그 앞의 배열에 순서대로 정렬되어 삽입되는 것을 확인할 수 있다.
퀵 정렬 (Quick Sort)
- 코드
이 코드에서는 size 값이 아니라 배열의 start, end 인덱스값을 인자로 주어야 한다.
void quick_sort(int arr[], int start, int end)
{
if (start >= end) //재귀함수 종료 조건
return;
int pivot = start; //pivot 설정
int left = start + 1;
int right = end;
while (left <= right) {
//left에서 arr[pivot]보다 큰 값 찾기
while (left < end && arr[left] < arr[pivot])
left++;
//right에서 arr[pivot]보다 작은 값 찾기
while (right > start && arr[right] >= arr[pivot])
right--;
if (left < right) {
//left와 right의 두 값 swqp
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
else {
//pivot과 더 작은 값인 right를 swap
int temp = arr[pivot];
arr[pivot] = arr[right];
arr[right] = temp;
}
}
//right를 기준으로 양 옆의 array를 재귀적으로 quick sort 진행
quick_sort(arr, start, right - 1);
quick_sort(arr, right + 1, end);
}
- 실행 결과 및 정렬 진행 과정

진행 과정이 더 많아보이지만 모든 SWAP을 표현한 것으로 함수 실행 및 수행 시간은 이보다 적다. 재귀함수 방식에 따라 앞 쪽 배열이 먼저 정리 되고 그 후 뒤쪽 배열이 정리된 것을 확인할 수 있다.
병합 정렬 (Merge Sort)
- 코드
void merge_sort(int arr[], int n)
{
//크기가 큰 배열이면 두 개의 작은 배열로 나누기
if (n > 2) {
merge_sort(arr, n / 2);
merge_sort(arr + (n / 2), n - (n / 2));
//merge
int left = 0, right = n / 2, i = 0;
int buff[500] = { 0, }; //배열을 합칠 때 사용할 새로운 임시공간
while (left < n / 2 && right < n) {
//더 작은 값을 버퍼에 넣으며 다음 값을 계속 비교한다.
if (arr[left] < arr[right])
buff[i++] = arr[left++];
else
buff[i++] = arr[right++];
}
//while문이 종료되어도 아직 남아있는 큰 값들을 전부 그 뒤에 넣는다.
//left와 right에 있는 작은 두 배열들은 각각 정렬되어있기 때문에 순서대로 집어넣어도 된다.
while (left < n / 2)
buff[i++] = arr[left++];
while (right < n)
buff[i++] = arr[right++];
//임시배열에 저장된 정렬된 배열을 원래 배열에 다시 저장
memcpy(arr, buff, sizeof(int) * n);
}
//n이 2보다 작으면 아무 동작하지 않고 종료.
//n이 2일 때
else if (n == 2) {
//두 값을 비교하여 swap으로 정렬
//n = 2일 때는 swap으로 정렬하는 것이 더 빠르다.
if (arr[0] > arr[1]) {
int temp = arr[0];
arr[0] = arr[1];
arr[1] = temp;
}
}
}
- 실행 결과 및 정렬 진행 과정
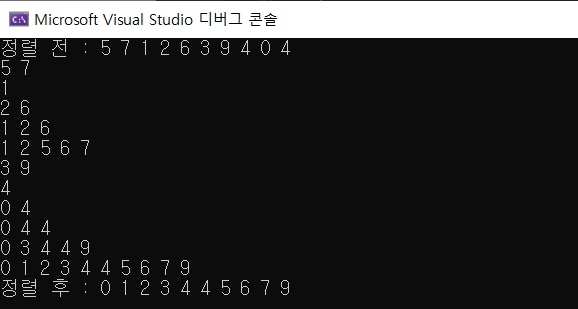
merge sort이기 때문에 부분배열부터 먼저 정렬된 다음 점점 큰 배열을 정렬하게 된다. 각 부분 배열도 모두 정렬되어있는 것을 확인할 수 있다.
4개 정렬 방식에 따른 시간 복잡도 비교
똑같은 내용의 배열을 4개의 정렬 방식으로 정렬하는데 각각 걸린 ms 시간이다. (같은 배열 복사하기 memcpy 함수 사용)
원소는 50000개로 0~50000까지의 원소를 정렬하였다.
Merge sort는 아마 메모리 문제때문인지 실행이 안되어서 위 코드 중 임시 배열 n에 맞게 동적할당하도록 바꾸어 실행하였다.
- 실행 결과
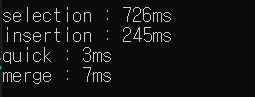
이 결과를 봤을 때는 퀵 소트가 4개 중 가장 효과적인 정렬 방법이라고 할 수 있다.
또 selection과 insertion은 둘 다 시간복잡도가 O(n^2)인데도 실행시간에 차이가 나는 것을 확인할 수 있었다.
'알고리즘 공부' 카테고리의 다른 글
| 그래프 최단 경로 탐색 알고리즘 - 다익스트라 (0) | 2021.05.02 |
|---|---|
| C++ 이진탐색 정리, 코드 (0) | 2021.04.11 |
| C++ 정렬(Sorting) 알고리즘 정리(1) - 이론 (0) | 2021.04.07 |
| C++ 그래프 탐색 알고리즘 기본 DFS/BFS 구현 (0) | 2021.04.07 |
| 대표적인 그래프 탐색 알고리즘 DFS/BFS 이론 (0) | 2021.04.07 |



댓글